
PandasのDataFrameでのデータ集計方法を、演習用プログラムのソースコードを使い、それを実行しながら解説します。
1.演習用プログラムのダウンロード
演習用プログラム( practice21.py )、2つのExcelファイル( 商品一覧.xlsx、販売実績.xlsx )をダウンロードします。
演習用プログラムは テキストファイルになっているので、エクスプローラーを使って拡張子を .txt から .py に変更します。
practice21.py、商品一覧.xlsx、販売実績.xlsx を Python をインストールしたフォルダ(今回は C:\Python)に置きます。
2.ソースコードの表示
メモ帳を使って、演習用プログラム( practice21.py )を開きます。
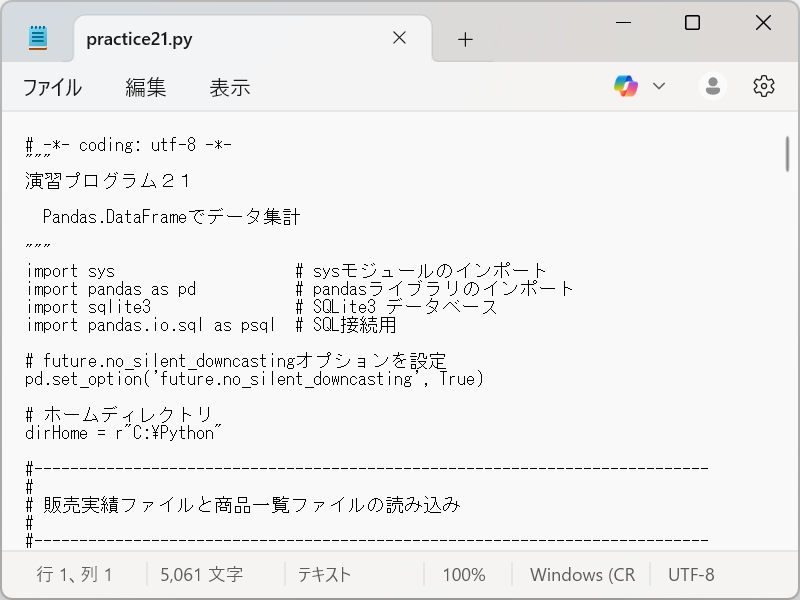
practice21.py
3.DataFrameでデータ集計
① 販売実績ファイルと商品一覧ファイルの読み込み
コマンドプロンプト で practice21.py を実行します。
プログラムを実行する方法は、こちらの記事『ファイルに保存されたプログラムの実行』を参照します。
以下のように表示されます。
#
# 販売実績ファイルと商品一覧ファイルの読み込み
#
販売実績ファイル名:C:\Python\販売実績.xlsx
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0002 3
2 202511 A0003 4
3 202511 A0007 2
4 202511 A0010 2
5 202512 A0001 4
6 202512 A0003 2
7 202512 A0004 1
8 202512 A0005 3
9 202512 A0006 5
10 202601 A0008 5
11 202601 A0010 1
12 202601 A0005 4
13 202601 A9999 3
14 202601 A0001 2
(行数:15、列数:3)
商品一覧ファイル名:C:\Python\商品一覧.xlsx
商品コード 商品名 単価 産地
0 A0001 みかん 100 和歌山
1 A0002 メロン 200 茨城県
2 A0003 レモン 300 広島県
3 A0004 りんご 400
4 A0005 バナナ 500 沖縄県
5 A0006 ぶどう 600 千葉県
6 A0007 スイカ 700 熊本県
7 A0008 イチゴ 800 栃木県
8 A0009 カシス 900
9 A0010 ライム 1000
(行数:10、列数:4)
販売実績ファイル(Excel)と商品一覧ファイル(Excel)を読み込んで、df販売実績(DataFrame)と df商品一覧(DataFrame)を作成します。
プログラムソースを確認します。
19 #---------------------------------------------------------------------------
20 #
21 # 販売実績ファイルと商品一覧ファイルの読み込み
22 #
23 #---------------------------------------------------------------------------
24
25 print("\n")
26 print("#")
27 print("# 販売実績ファイルと商品一覧ファイルの読み込み")
28 print("#")
29
30 # 販売実績ファイルの読み込み
31 filename = dirHome + r"\販売実績.xlsx"
32 print("\n販売実績ファイル名:" + filename + "\n")
33
34 # DataFrameを作成
35 df販売実績 = pd.read_excel(filename, sheet_name = 'Sheet1', dtype = object)
36
37 print(df販売実績)
38 print("(行数:" + str(df販売実績.shape[0]) + "、列数:" + str(df販売実績.shape[1]) + ")")
39
40
41 # 商品一覧ファイルの読み込み
42 filename = dirHome + r"\商品一覧.xlsx"
43 print("\n商品一覧ファイル名:" + filename + "\n")
44
45 # DataFrameを作成
46 df商品一覧 = pd.read_excel(filename, sheet_name = 'Sheet3', dtype = object)
47
48 # 欠損値を空文字で埋める
49 df商品一覧 = df商品一覧.fillna("")
50
51 print(df商品一覧)
52 print("(行数:" + str(df商品一覧.shape[0]) + "、列数:" + str(df商品一覧.shape[1]) + ")")
53
54 #終了1
55 sys.exit()
35行目で、販売実績ファイルを読み込んで、df販売実績(DataFrame)を作成しています。
46行目で、商品一覧ファイルを読み込んで、df商品一覧(DataFrame)を作成しています。
df商品一覧 には欠損値(NaN)が含まれているので、49行目で fillna() を使って空文字で埋めています。
② 販売実績ファイルに商品一覧ファイルを結合(横方向)
ソースコード #終了1 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
#
# 販売実績ファイルに商品一覧ファイルを結合(横方向)
#
*** 商品コードをキーにして左外部結合(how = 'left')***
年月 商品コード 数量 商品名 単価 産地
0 202511 A0001 8 みかん 100 和歌山
1 202511 A0002 3 メロン 200 茨城県
2 202511 A0003 4 レモン 300 広島県
3 202511 A0007 2 スイカ 700 熊本県
4 202511 A0010 2 ライム 1000
5 202512 A0001 4 みかん 100 和歌山
6 202512 A0003 2 レモン 300 広島県
7 202512 A0004 1 りんご 400
8 202512 A0005 3 バナナ 500 沖縄県
9 202512 A0006 5 ぶどう 600 千葉県
10 202601 A0008 5 イチゴ 800 栃木県
11 202601 A0010 1 ライム 1000
12 202601 A0005 4 バナナ 500 沖縄県
13 202601 A9999 3 NaN NaN NaN
14 202601 A0001 2 みかん 100 和歌山
(行数:15、列数:6)
商品コードをキーにして、販売実績ファイルに商品一覧ファイルを結合しています。
プログラムソースを確認します。
58 #---------------------------------------------------------------------------
59 #
60 # 販売実績ファイルに商品一覧ファイルを結合(横方向)
61 #
62 #---------------------------------------------------------------------------
63
64 print("\n")
65 print("#")
66 print("# 販売実績ファイルに商品一覧ファイルを結合(横方向)")
67 print("#")
68
69 # 商品コードをキーにして左外部結合(how = 'left')
70 print("\n*** 商品コードをキーにして左外部結合(how = 'left')***\n")
71 df結合 = pd.merge(df販売実績, df商品一覧, on = '商品コード', how = 'left')
72
73 print(df結合)
74 print("(行数:" + str(df結合.shape[0]) + "、列数:" + str(df結合.shape[1]) + ")")
75
76 #終了2
77 sys.exit()
71行目で、merge() を使い、商品コードをキー( on = '商品コード' )にして、販売実績ファイルに商品一覧ファイルを結合しています。
③ 不要なデータを削除
ソースコード #終了2 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
#
# 不要なデータを削除
#
*** 商品名、単価のいずれかに欠損値(NaN)が含まれる行を削除 ***
年月 商品コード 数量 商品名 単価 産地
0 202511 A0001 8 みかん 100 和歌山
1 202511 A0002 3 メロン 200 茨城県
2 202511 A0003 4 レモン 300 広島県
3 202511 A0007 2 スイカ 700 熊本県
4 202511 A0010 2 ライム 1000
5 202512 A0001 4 みかん 100 和歌山
6 202512 A0003 2 レモン 300 広島県
7 202512 A0004 1 りんご 400
8 202512 A0005 3 バナナ 500 沖縄県
9 202512 A0006 5 ぶどう 600 千葉県
10 202601 A0008 5 イチゴ 800 栃木県
11 202601 A0010 1 ライム 1000
12 202601 A0005 4 バナナ 500 沖縄県
14 202601 A0001 2 みかん 100 和歌山
(行数:14、列数:6)
*** 産地の列を削除 ***
年月 商品コード 数量 商品名 単価
0 202511 A0001 8 みかん 100
1 202511 A0002 3 メロン 200
2 202511 A0003 4 レモン 300
3 202511 A0007 2 スイカ 700
4 202511 A0010 2 ライム 1000
5 202512 A0001 4 みかん 100
6 202512 A0003 2 レモン 300
7 202512 A0004 1 りんご 400
8 202512 A0005 3 バナナ 500
9 202512 A0006 5 ぶどう 600
10 202601 A0008 5 イチゴ 800
11 202601 A0010 1 ライム 1000
12 202601 A0005 4 バナナ 500
14 202601 A0001 2 みかん 100
(行数:14、列数:5)
欠損値(NaN)が含まれる行(インデックス 13)を削除して、産地 の列を削除しています。
プログラムソースを確認します。
80 #---------------------------------------------------------------------------
81 #
82 # 不要なデータを削除
83 #
84 #---------------------------------------------------------------------------
85
86 print("\n")
87 print("#")
88 print("# 不要なデータを削除")
89 print("#")
90
91 # 不要な行を削除
92 print("\n*** 商品名、単価のいずれかに欠損値(NaN)が含まれる行を削除 ***\n")
93 df結合 = df結合.dropna(subset = ['商品名','単価'])
94
95 print(df結合)
96 print("(行数:" + str(df結合.shape[0]) + "、列数:" + str(df結合.shape[1]) + ")")
97
98
99 # 産地の列を削除
100 print("\n*** 産地の列を削除 ***\n")
101 df結合 = df結合.drop('産地', axis = 1)
102
103 print(df結合)
104 print("(行数:" + str(df結合.shape[0]) + "、列数:" + str(df結合.shape[1]) + ")")
105
106 #終了3
107 sys.exit()
93行目の dropna() と subsetパラメータで、商品名、単価のいずれかに欠損値(NaN)が含まれる行を削除しています
101行目で、産地 の列を削除しています。axisパラメータに 1 をセットすると列の削除になります。
④ 販売額(単価×数量)の列を追加
ソースコード #終了3 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
#
# 販売額(単価×数量)の列を追加
#
年月 商品コード 数量 商品名 単価 販売額
0 202511 A0001 8 みかん 100 800
1 202511 A0002 3 メロン 200 600
2 202511 A0003 4 レモン 300 1200
3 202511 A0007 2 スイカ 700 1400
4 202511 A0010 2 ライム 1000 2000
5 202512 A0001 4 みかん 100 400
6 202512 A0003 2 レモン 300 600
7 202512 A0004 1 りんご 400 400
8 202512 A0005 3 バナナ 500 1500
9 202512 A0006 5 ぶどう 600 3000
10 202601 A0008 5 イチゴ 800 4000
11 202601 A0010 1 ライム 1000 1000
12 202601 A0005 4 バナナ 500 2000
14 202601 A0001 2 みかん 100 200
(行数:14、列数:6)
プログラムソースを確認します。
110 #---------------------------------------------------------------------------
111 #
112 # 販売額(単価×数量)の列を追加
113 #
114 #---------------------------------------------------------------------------
115
116 print("\n")
117 print("#")
118 print("# 販売額(単価×数量)の列を追加")
119 print("#")
120
121 df結合['販売額'] = df結合['単価'] * df結合['数量']
122
123 print(df結合)
124 print("(行数:" + str(df結合.shape[0]) + "、列数:" + str(df結合.shape[1]) + ")")
125
126 #終了4
127 sys.exit()
121行目で、単価×数量 の計算結果を 販売額 の列に追加しています。
⑤ 年月毎に販売額を集計
ソースコード #終了4 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
#
# 年月毎に販売額を集計
#
解説:
DataFrame.groupby('グループ化したい列名')['集計したい列名'].集計関数()
年月
202511 6000
202512 5900
202601 7200
Name: 販売額, dtype: object
(行数:3)
プログラムソースを確認します。
130 #---------------------------------------------------------------------------
131 #
132 # 年月毎に販売額を集計
133 #
134 #---------------------------------------------------------------------------
135
136 print("\n")
137 print("#")
138 print("# 年月毎に販売額を集計")
139 print("#")
140
141 print("\n解説:")
142 print("DataFrame.groupby('グループ化したい列名')['集計したい列名'].集計関数()\n")
143
144 result = df結合.groupby('年月')['販売額'].sum()
145
146 print(result)
147 print("(行数:" + str(len(result)) + ")") # len()は要素の数を返す関数
148
149 #終了5
150 sys.exit()
144行で、年月毎に販売額を集計しています。
groupby('グループ化したい列名')['集計したい列名'].集計関数()
グループ化したい列名 → 年月
集計したい列名 → 販売額
集計関数() → sum()
⑥ 商品毎に販売額を集計
ソースコード #終了5 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # 商品毎に販売額を集計 # *** 商品毎に販売額を集計 *** 商品コード A0001 1400 A0002 600 A0003 1800 A0004 400 A0005 3500 A0006 3000 A0007 1400 A0008 4000 A0010 3000 Name: 販売額, dtype: object (行数:9) *** 商品名の列を追加 *** 商品コード 商品名 販売額 0 A0001 みかん 1400 1 A0002 メロン 600 2 A0003 レモン 1800 3 A0004 りんご 400 4 A0005 バナナ 3500 5 A0006 ぶどう 3000 6 A0007 スイカ 1400 7 A0008 イチゴ 4000 8 A0010 ライム 3000 (行数:9、列数:3)
商品毎に販売額を集計後に、商品一覧から商品コードをキーにして商品名を取得しています。
プログラムソースを確認します。
153 #---------------------------------------------------------------------------
154 #
155 # 商品毎に販売額を集計
156 #
157 #---------------------------------------------------------------------------
158
159 print("\n")
160 print("#")
161 print("# 商品毎に販売額を集計")
162 print("#")
163
164 # 商品毎に販売額を集計
165 print("\n*** 商品毎に販売額を集計 ***\n")
166 sri商品集計 = df結合.groupby('商品コード')['販売額'].sum()
167
168 print(sri商品集計)
169 print("(行数:" + str(len(sri商品集計)) + ")") # len()は要素の数を返す関数
170
171 # 商品名の列を追加
172 print("\n*** 商品名の列を追加 ***\n")
173 # 商品一覧と結合
174 df商品集計 = pd.merge(sri商品集計, df商品一覧, on = '商品コード', how = 'left')
175
176 # 必要な列を選択
177 df商品集計 = df商品集計[['商品コード','商品名','販売額']]
178
179 print(df商品集計)
180 print("(行数:" + str(df商品集計.shape[0]) + "、列数:" + str(df商品集計.shape[1]) + ")")
181
182 #終了6
183 sys.exit()
166行目で、商品毎に販売額を集計しています。
groupby('グループ化したい列名')['集計したい列名'].集計関数()
グループ化したい列名 → 商品コード
集計したい列名 → 販売額
集計関数() → sum()
商品名の列を追加するために、174行目で、merge() を使い、商品コードをキー( on = '商品コード' )にして、商品一覧ファイルを結合しています。
177行目で、必要な列(商品コード、商品名、販売額)のみにしています。
4.SQL文を使った集計
① SQL文を使うための準備
SQLite「組み込み型のリレーショナルデータベース」を使います。
Pythonにはじめから SQLite(sqlite3 モジュール)が含まれています。
準備手順
・sqlite3 モジュール と pandas.io.sql モジュール を import します。
pandas.io.sql とは、PandasのDataFrameとSQLデータベースの間でデータをやり取りするためのモジュールです。
・sqlite3 を作成します。
・DataFrameをsqlite3にテーブルとして格納します。
ソースコード #終了6 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
#
# SQL文を使った集計
#
販売実績のデータ
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0002 3
2 202511 A0003 4
3 202511 A0007 2
4 202511 A0010 2
5 202512 A0001 4
6 202512 A0003 2
7 202512 A0004 1
8 202512 A0005 3
9 202512 A0006 5
10 202601 A0008 5
11 202601 A0010 1
12 202601 A0005 4
13 202601 A9999 3
14 202601 A0001 2
(行数:15、列数:3)
商品一覧のデータ
商品コード 商品名 単価 産地
0 A0001 みかん 100 和歌山
1 A0002 メロン 200 茨城県
2 A0003 レモン 300 広島県
3 A0004 りんご 400
4 A0005 バナナ 500 沖縄県
5 A0006 ぶどう 600 千葉県
6 A0007 スイカ 700 熊本県
7 A0008 イチゴ 800 栃木県
8 A0009 カシス 900
9 A0010 ライム 1000
(行数:10、列数:4)
プログラムソースを確認します。
10 import sqlite3 # SQLite3 データベース
11 import pandas.io.sql as psql # SQL接続用
186 #---------------------------------------------------------------------------
187 #
188 # SQL文を使った集計
189 #
190 #---------------------------------------------------------------------------
191
192 print("\n")
193 print("#")
194 print("# SQL文を使った集計")
195 print("#")
196
197 # sqlite3を作成
198 connection = sqlite3.connect(':memory:')
199 connection.isolation_level = None # Noneで自動コミットモード
200 cursor = connection.cursor()
201
202 # DataFrameをsqlite3にテーブルとして格納
203 df販売実績.to_sql('販売実績', connection, if_exists = 'append', index = None)
204 df商品一覧.to_sql('商品一覧', connection, if_exists = 'append', index = None)
205
206 # 販売実績のデータを全て取得
207 select_query = """
208 SELECT * FROM 販売実績;
209 """
210 df結果 = psql.read_sql(select_query, connection)
211
212 print("\n販売実績のデータ")
213 print(df結果)
214 print("(行数:" + str(df結果.shape[0]) + "、列数:" + str(df結果.shape[1]) + ")")
215
216 # 商品一覧のデータを全て取得
217 select_query = """
218 SELECT * FROM 商品一覧;
219 """
220 df結果 = psql.read_sql(select_query, connection)
221
222 print("\n商品一覧のデータ")
223 print(df結果)
224 print("(行数:" + str(df結果.shape[0]) + "、列数:" + str(df結果.shape[1]) + ")")
225
226 #終了7
227 sys.exit()
10行目で、sqlite3 を import しています。
11行目で、pandas.io.sql を import しています。
198行目~200行目で、sqlite3 を作成しています。
203行目で 販売実績(DataFrame)を、204行目で 商品一覧(DataFrame)を sqlite3 のテーブルとして格納しています。
208行目で 販売実績テーブルの全件データを取得するSQL文を用意しています。
210行目で SQL文を実行して、販売実績の全件データ(DataFrame)を取得しています。
218行目で 商品一覧テーブルの全件データを取得するSQL文を用意しています。
220行目で SQL文を実行して、商品一覧の全件データ(DataFrame)を取得しています。
② 年月毎に販売額を集計
SQL文を使って、年月毎に販売額を集計します。
ソースコード #終了7 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 年月毎に販売額を集計 ***
年月 販売額
0 202511 6000
1 202512 5900
2 202601 7200
(行数:3、列数:2)
プログラムソースを確認します。
230 # 年月毎に販売額を集計
231 print("\n*** 年月毎に販売額を集計 ***\n")
232
233 select_query = """
234 SELECT
235 A.年月,
236 SUM(B.単価 * A.数量) as 販売額
237 FROM 販売実績 as A,
238 商品一覧 as B
239 WHERE A.商品コード = B.商品コード
240 GROUP BY A.年月;
241 """
242 df結果 = psql.read_sql(select_query, connection)
243
244 print(df結果)
245 print("(行数:" + str(df結果.shape[0]) + "、列数:" + str(df結果.shape[1]) + ")")
246
247 #終了8
248 sys.exit()
233行目~241行目で、年月毎に販売額を集計するSQL文を用意しています。
242行目で、SQL文を実行して、集計結果を df結果(DataFrame)に格納しています。
③ 商品毎に販売額を集計
SQL文を使って、商品毎に販売額を集計します。
ソースコード #終了8 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 商品毎に販売額を集計 *** 商品コード 商品名 販売額 0 A0001 みかん 1400 1 A0002 メロン 600 2 A0003 レモン 1800 3 A0004 りんご 400 4 A0005 バナナ 3500 5 A0006 ぶどう 3000 6 A0007 スイカ 1400 7 A0008 イチゴ 4000 8 A0010 ライム 3000 (行数:9、列数:3)
プログラムソースを確認します。
251 # 商品毎に販売額を集計
252 print("\n*** 商品毎に販売額を集計 ***\n")
253
254 select_query = """
255 SELECT
256 A.商品コード as 商品コード,
257 B.商品名 as 商品名,
258 SUM(B.単価 * A.数量) as 販売額
259 FROM 販売実績 as A,
260 商品一覧 as B
261 WHERE A.商品コード = B.商品コード
262 GROUP BY A.商品コード;
263 """
264 df結果 = psql.read_sql(select_query, connection)
265
266 print(df結果)
267 print("(行数:" + str(df結果.shape[0]) + "、列数:" + str(df結果.shape[1]) + ")")
268
269 sys.exit()
254行目~263行目で、商品毎に販売額を集計するSQL文を用意しています。
264行目で、SQL文を実行して、集計結果を df結果(DataFrame)に格納しています。
| <Pandas.DataFrameの利用 | Pandas.DataFrameでデータ集計 |
