
PandasのDataFrameの利用方法を、演習用プログラムのソースコードを使い、それを実行しながら解説します。
1.演習用プログラムのダウンロード
演習用プログラム( practice20.py )、2つのExcelファイル( 商品一覧.xlsx、販売実績.xlsx )をダウンロードします。
演習用プログラムは テキストファイルになっているので、エクスプローラーを使って拡張子を .txt から .py に変更します。
practice20.py、商品一覧.xlsx、販売実績.xlsx を Python をインストールしたフォルダ(今回は C:\Python)に置きます。
2.ソースコードの表示
メモ帳を使って、演習用プログラム( practice20.py )を開きます。
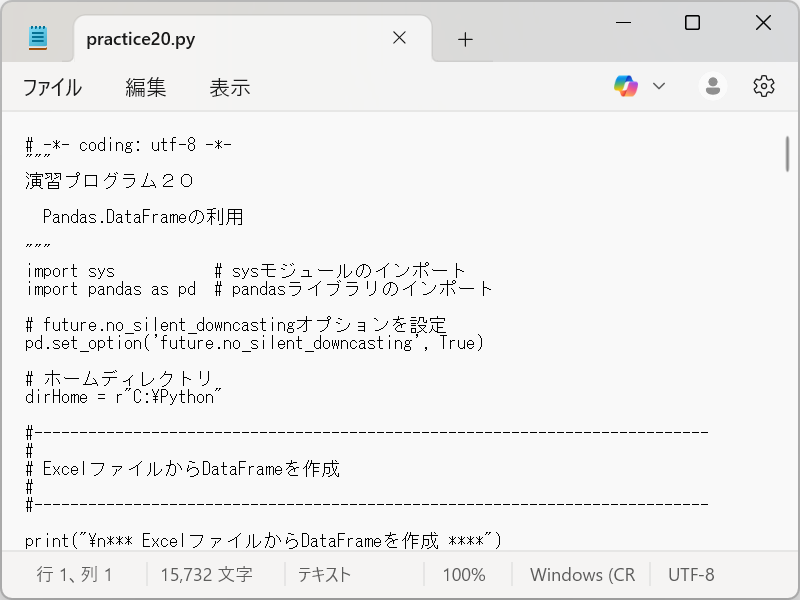
practice20.py
3.データの取り出し
① ExcelファイルからDataFrameを作成
コマンドプロンプト で practice20.py を実行します。
プログラムを実行する方法は、こちらの記事『ファイルに保存されたプログラムの実行』を参照します。
以下のように表示されます。
*** ExcelファイルからDataFrameを作成 **** 商品一覧ファイル名:C:\Python\商品一覧.xlsx 商品コード 商品名 単価 産地 0 A0001 みかん 100 和歌山 1 A0002 メロン 200 茨城県 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 4 A0005 バナナ 500 沖縄県 (行数:5、列数:4)
Excelファイル(商品一覧.xlsx)を読み込んで、5行4列のDataFrameを作成しました。
プログラムソースを確認します。
17 #---------------------------------------------------------------------------
18 #
19 # ExcelファイルからDataFrameを作成
20 #
21 #---------------------------------------------------------------------------
22
23 print("\n*** ExcelファイルからDataFrameを作成 ****")
24
25 filename = dirHome + r"\商品一覧.xlsx"
26 print("\n商品一覧ファイル名:" + filename + "\n")
27
28 # DataFrameを作成
29 df商品一覧 = pd.read_excel(filename, sheet_name = 'Sheet1')
30
31 print(df商品一覧)
32 print("(行数:" + str(df商品一覧.shape[0]) + "、列数:" + str(df商品一覧.shape[1]) + ")")
33 #print(df商品一覧.dtypes) # 項目毎のデータ型
34
35 #終了1
36 #sys.exit()
29行目の read_excel() で、ExcelファイルからDataFrameを作成しています。
② 列データの取り出し
ソースコード #終了1 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # 列データの取り出し # *** 商品名の列をSeriesとして取り出す *** 0 みかん 1 メロン 2 レモン 3 りんご 4 バナナ Name: 商品名, dtype: object (行数:5) <class 'pandas.core.series.Series'> *** 商品名の列をDataFrameとして取り出す *** 商品名 0 みかん 1 メロン 2 レモン 3 りんご 4 バナナ (行数:5、列数:1) <class 'pandas.core.frame.DataFrame'> *** 商品名の文字数を取り出す *** 0 3 1 3 2 3 3 3 4 3 Name: 商品名, dtype: int64 (行数:5) <class 'pandas.core.series.Series'> *** 商品名の先頭1文字取り出す *** 0 み 1 メ 2 レ 3 り 4 バ Name: 商品名, dtype: object (行数:5) <class 'pandas.core.series.Series'>
プログラムソースを確認します。
50 # 列データの取り出し(Series)
51 print("\n*** 商品名の列をSeriesとして取り出す ***\n")
52 sri = df商品一覧['商品名']
列データを Series で取り出す
52行目の df商品一覧['商品名'] とすることで商品名の列を Series で取り出せます。
58 # 列データの取り出し(DataFrame)
59 print("\n*** 商品名の列をDataFrameとして取り出す ***\n")
60 df = df商品一覧[['商品名']]
列データを DataFrame で取り出す
60行目の df商品一覧[['商品名']] とすることで商品名の列を DataFrame で取り出せます。
66 # 商品名の文字数を取り出す
67 print("\n*** 商品名の文字数を取り出す ***\n")
68 sri= df商品一覧['商品名'].str.len()
商品名の文字数を取り出す
68行目の df商品一覧['商品名'].str.len() とすることでそれぞれの行の商品名の文字数を取り出せます。
74 # 商品名の先頭1文字取り出す
75 print("\n*** 商品名の先頭1文字取り出す ***\n")
76 sri= df商品一覧['商品名'].str[:1]
82 #終了2
83 #sys.exit()
商品名の先頭1文字取り出す
76行目の df商品一覧['商品名'].str[:1] でスライスを使って、それぞれの行の商品名の先頭1文字を取り出しています。
③ 複数の列データの取り出し
ソースコード #終了2 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 商品コードと単価の列を取り出す *** 商品コード 単価 0 A0001 100 1 A0002 200 2 A0003 300 3 A0004 400 4 A0005 500 (行数:5、列数:2) <class 'pandas.core.frame.DataFrame'>
商品コードと単価の列を DataFrame で取り出しています。
プログラムソースを確認します。
86 # 複数の列データの取り出し
87 print("\n*** 商品コードと単価の列を取り出す ***\n")
88 df = df商品一覧[['商品コード','単価']]
89
94 #終了3
95 #sys.exit()
88行目で、商品コードと単価の項目名をリストで指定して、2列を取り出しています。
④ loc を使い、行を指定してデータを取り出す
ソースコード #終了3 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # 行を指定してデータを取り出し(DataFrame.loc) # 解説: DataFrame.loc[行の指定] 商品コード 単価 0 A0001 100 1 A0002 200 2 A0003 300 3 A0004 400 4 A0005 500 (行数:5、列数:2) *** インデックスが 1 の行データを取り出す *** 商品コード 単価 1 A0002 200 *** インデックスが 1と3 の行データを取り出す *** 商品コード 単価 1 A0002 200 3 A0004 400 *** インデックスが 1~3 の行データを取り出す *** 商品コード 単価 1 A0002 200 2 A0003 300 3 A0004 400
| インデックス | 商品コード | 単価 |
| 0 | A0001 | 100 |
| 1 | A0002 | 200 |
| 2 | A0003 | 300 |
| 3 | A0004 | 400 |
| 4 | A0005 | 500 |
loc を使って、行(インデックス)を指定してデータを取り出す場合
loc[行の指定]
プログラムソースを確認します。
115 print("\n*** インデックスが 1 の行データを取り出す ***\n")
116 print(df.loc[[1]])
インデックスが 1 の行データを取り出す
116行目で loc[] に、インデックス 1 が1つ入ったリスト [1] を指定しています。 loc[[1]]
118 print("\n*** インデックスが 1と3 の行データを取り出す ***\n")
119 print(df.loc[[1, 3]])
インデックスが 1と3 の行データを取り出す
119行目で loc[] に、インデックス 1 と 3 が入ったリスト [1, 3] を指定しています。 loc[[1, 3]]
121 print("\n*** インデックスが 1~3 の行データを取り出す ***\n")
122 print(df.loc[1:3])
123
124 #終了4
125 #sys.exit()
インデックスが 1~3 の行データを取り出す
122行目で loc[] に、インデックス 1 から 3 が入ったスライス 1:3 を指定しています。 loc[1:3]
⑤ loc を使い、行と列を指定してデータを取り出す
ソースコード #終了4 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # 行、列を指定してデータを取り出し(DataFrame.loc) # 解説: DataFrame.loc[行の指定, 列の指定] 商品コード 単価 0 A0001 100 1 A0002 200 2 A0003 300 3 A0004 400 4 A0005 500 (行数:5、列数:2) *** インデックスが 1 の商品コードを取り出す *** A0002 *** インデックスが 1と3 の商品コードを取り出す *** 1 A0002 3 A0004 Name: 商品コード, dtype: object *** インデックスが 1と3 の商品コードと単価を取り出す *** 商品コード 単価 1 A0002 200 3 A0004 400 *** インデックスが 1~3 の商品コードを取り出す *** 1 A0002 2 A0003 3 A0004 Name: 商品コード, dtype: object *** すべての行の商品コードと単価を取り出す *** 商品コード 単価 0 A0001 100 1 A0002 200 2 A0003 300 3 A0004 400 4 A0005 500
| インデックス | 商品コード | 単価 |
| 0 | A0001 | 100 |
| 1 | A0002 | 200 |
| 2 | A0003 | 300 |
| 3 | A0004 | 400 |
| 4 | A0005 | 500 |
loc を使って、行(インデックス)と列(列名)を指定してデータを取り出す場合
loc[行の指定, 列の指定]
プログラムソースを確認します。
145 print("\n*** インデックスが 1 の商品コードを取り出す ***\n")
146 print(df.loc[1, '商品コード'])
インデックスが 1 の商品コードを取り出す
146行目の loc[行の指定, 列の指定] に、行の指定 を 1、列の指定 を 商品コード にしています。 loc[1, '商品コード']
148 print("\n*** インデックスが 1と3 の商品コードを取り出す ***\n")
149 print(df.loc[[1, 3], '商品コード'])
インデックスが 1と3 の商品コードを取り出す
149行目の loc[行の指定, 列の指定] に、行の指定 を 1と3 の入ったリスト、列の指定 を 商品コード にしています。 loc[[1, 3], '商品コード']
151 print("\n*** インデックスが 1と3 の商品コードと単価を取り出す ***\n")
152 print(df.loc[[1, 3], ['商品コード', '単価']])
インデックスが 1と3 の商品コードと単価を取り出す
152行目の loc[行の指定, 列の指定] に、行の指定 を 1と3 の入ったリスト、列の指定 を 商品コードと単価 の入ったリストにしています。 loc[[1, 3], ['商品コード', '単価']]
154 print("\n*** インデックスが 1~3 の商品コードを取り出す ***\n")
155 print(df.loc[1:3, '商品コード'])
インデックスが 1~3 の商品コードを取り出す
155行目の loc[行の指定, 列の指定] に、行の指定 を 1から3 のスライス、列の指定 を 商品コード にしています。 loc[1:3, '商品コード']
157 print("\n*** すべての行の商品コードと単価を取り出す ***\n")
158 print(df.loc[:, ['商品コード', '単価']])
159
160 #終了5
161 #sys.exit()
すべての行の商品コードと単価を取り出す
158行目の loc[行の指定, 列の指定] に、行の指定 を 全行(スライスの『 : 』)、列の指定 を 商品コードと単価 の入ったリストにしています。 loc[:, ['商品コード', '単価']]
⑥ iloc を使い、行を指定してデータを取り出す
ソースコード #終了5 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # 行を指定してデータを取り出し(DataFrame.iloc) # 解説: DataFrame.iloc[行の指定] 商品コード 単価 0 A0001 100 1 A0002 200 2 A0003 300 3 A0004 400 4 A0005 500 (行数:5、列数:2) *** 行番号が 1 の行データを取り出す *** 商品コード 単価 1 A0002 200 *** 行番号が 1と3 の行データを取り出す *** 商品コード 単価 1 A0002 200 3 A0004 400 *** 行番号が 1~2 の行データを取り出す *** 商品コード 単価 1 A0002 200 2 A0003 300
| 行番号 | インデックス | 商品コード | 単価 |
| 0 | 0 | A0001 | 100 |
| 1 | 1 | A0002 | 200 |
| 2 | 2 | A0003 | 300 |
| 3 | 3 | A0004 | 400 |
| 4 | 4 | A0005 | 500 |
iloc を使って、行番号(ゼロから始まる番号)を指定してデータを取り出す場合
iloc[行の指定]
プログラムソースを確認します。
181 print("\n*** 行番号が 1 の行データを取り出す ***\n")
182 print(df.iloc[[1]])
行番号が 1 の行データを取り出す
182行目で iloc[] に、行番号 1 が1つ入ったリスト [1] を指定しています。 iloc[[1]]
184 print("\n*** 行番号が 1と3 の行データを取り出す ***\n")
185 print(df.iloc[[1, 3]])
行番号が 1と3 の行データを取り出す
185行目で iloc[] に、行番号 1 と 3 が入ったリスト [1, 3] を指定しています。 iloc[[1, 3]]
187 print("\n*** 行番号が 1~2 の行データを取り出す ***\n")
188 print(df.iloc[1:3])
189
190 #終了6
191 #sys.exit()
行番号が 1~2 の行データを取り出す
188行目で iloc[] に、行番号 1 から 3 が入ったスライス 1:3 を指定しています。 iloc[1:3]
⑦ iloc を使い、行と列を指定してデータを取り出す
ソースコード #終了6 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # 行、列を指定してデータを取り出し(DataFrame.iloc) # 解説: DataFrame.iloc[行の指定, 列の指定] 商品コード 単価 0 A0001 100 1 A0002 200 2 A0003 300 3 A0004 400 4 A0005 500 (行数:5、列数:2) *** 行番号が 1 、列番号が 0(商品コード)のデータを取り出す *** A0002 *** 行番号が 1と3 、列番号が 0(商品コード)のデータを取り出す *** 1 A0002 3 A0004 Name: 商品コード, dtype: object *** 行番号が 1と3 、列番号が 0(商品コード)と 1(単価)のデータを取り出す *** 商品コード 単価 1 A0002 200 3 A0004 400 *** 行番号が 1~2 、列番号が 0(商品コード)のデータを取り出す *** 1 A0002 2 A0003 Name: 商品コード, dtype: object *** すべての行の列番号が 0(商品コード)と 1(単価)のデータを取り出す *** 商品コード 単価 0 A0001 100 1 A0002 200 2 A0003 300 3 A0004 400 4 A0005 500
| 列番号 | 0 | 1 | |
| 行番号 | インデックス | 商品コード | 単価 |
| 0 | 0 | A0001 | 100 |
| 1 | 1 | A0002 | 200 |
| 2 | 2 | A0003 | 300 |
| 3 | 3 | A0004 | 400 |
| 4 | 4 | A0005 | 500 |
iloc を使って、行番号(ゼロから始まる番号)と、列番号(ゼロから始まる番号)を指定してデータを取り出す場合
iloc[行番号, 列番号]
プログラムソースを確認します。
211 print("\n*** 行番号が 1 、列番号が 0(商品コード)のデータを取り出す ***\n")
212 print(df.iloc[1, 0])
行番号が 1 、列番号が 0(商品コード)のデータを取り出す
212行目の iloc[行番号, 列番号] に、行番号 を 1、列番号 を 0 にしています。 iloc[1, 0]
214 print("\n*** 行番号が 1と3 、列番号が 0(商品コード)のデータを取り出す ***\n")
215 print(df.iloc[[1, 3], 0])
行番号が 1と3 、列番号が 0(商品コード)のデータを取り出す
215行目の iloc[行番号, 列番号] に、行番号 を 1と3 の入ったリスト、列番号 を 0 にしています。 iloc[[1, 3], 0]
217 print("\n*** 行番号が 1と3 、列番号が 0(商品コード)と 1(単価)のデータを取り出す ***\n")
218 print(df.iloc[[1, 3], [0, 1]])
行番号が 1と3 、列番号が 0(商品コード)と 1(単価)のデータを取り出す
218行目の iloc[行番号, 列番号] に、行番号 を 1と3 の入ったリスト、列番号 を 0と1 の入ったリストにしています。 iloc[[1, 3], [0, 1]]
220 print("\n*** 行番号が 1~2 、列番号が 0(商品コード)のデータを取り出す ***\n")
221 print(df.iloc[1:3, 0])
行番号が 1~2 、列番号が 0(商品コード)のデータを取り出す
221行目の iloc[行番号, 列番号] に、行番号 を 1から3 のスライス、列番号 を 0 にしています。 iloc[1:3, 0]
223 print("\n*** すべての行の列番号が 0(商品コード)と 1(単価)のデータを取り出す ***\n")
224 print(df.iloc[:, [0, 1]])
225
226 #終了7
227 #sys.exit()
すべての行の列番号が 0(商品コード)と 1(単価)のデータを取り出す
224行目の iloc[行番号, 列番号] に、行番号 を 全行(スライスの『 : 』)、列番号 を 0と1 の入ったリストにしています。 iloc[:, [0, 1]]
4.データの絞り込み
① 数値条件を指定したデータの絞り込み
ソースコード #終了7 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # 条件を指定したデータの絞り込み # 商品コード 商品名 単価 産地 0 A0001 みかん 100 和歌山 1 A0002 メロン 200 茨城県 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 4 A0005 バナナ 500 沖縄県 (行数:5、列数:4) *** 単価が 200 より大きなデータを取り出す *** 商品コード 商品名 単価 産地 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 4 A0005 バナナ 500 沖縄県 *** 単価が 200 より大きくて 500 より小さなデータを取り出す(and条件:& )*** 商品コード 商品名 単価 産地 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 *** 単価が 200 より小さいか 400 より大きなデータを取り出す(or条件:| )*** 商品コード 商品名 単価 産地 0 A0001 みかん 100 和歌山 4 A0005 バナナ 500 沖縄県
プログラムソースを確認します。
245 print("\n*** 単価が 200 より大きなデータを取り出す ***\n")
246 result = df商品一覧[df商品一覧['単価'] > 200]
247 print(result)
単価が 200 より大きなデータを取り出す
246行目で、条件式を df商品一覧['単価'] > 200 としています。
249 print("\n*** 単価が 200 より大きくて 500 より小さなデータを取り出す(and条件:& )***\n")
250 result = df商品一覧[(df商品一覧['単価'] > 200) & (df商品一覧['単価'] < 500)]
251 print(result)
単価が 200 より大きくて 500 より小さなデータを取り出す
250行目で、条件式を (df商品一覧['単価'] > 200) & (df商品一覧['単価'] < 500) としています。
253 print("\n*** 単価が 200 より小さいか 400 より大きなデータを取り出す(or条件:| )***\n")
254 result = df商品一覧[(df商品一覧['単価'] < 200) | (df商品一覧['単価'] > 400)]
255 print(result)
256
257 #終了8
258 #sys.exit()
単価が 200 より小さいか 400 より大きなデータを取り出す
254行目で、条件式を (df商品一覧['単価'] < 200) | (df商品一覧['単価'] > 400) としています。
② 文字条件を指定したデータの絞り込み
ソースコード #終了8 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 商品名が3文字以上のデータを取り出す(str.len)***
DataFrame[DataFrame[列名].str.len() >= 3]
商品コード 商品名 単価 産地
0 A0001 みかん 100 和歌山
1 A0002 メロン 200 茨城県
2 A0003 レモン 300 広島県
3 A0004 りんご 400 青森県
4 A0005 バナナ 500 沖縄県
*** 商品名の先頭が'み'で始まるデータを取り出す(str.startswith)***
DataFrame[DataFrame[列名].str.startswith('み')]
商品コード 商品名 単価 産地
0 A0001 みかん 100 和歌山
*** 商品名に'ン'を含むデータを取り出す(str.contains)***
DataFrame[DataFrame[列名].str.contains('ン')]
商品コード 商品名 単価 産地
1 A0002 メロン 200 茨城県
2 A0003 レモン 300 広島県
プログラムソースを確認します。
261 # 商品名が3文字以上のデータを取り出す(str.len)
262 print("\n*** 商品名が3文字以上のデータを取り出す(str.len)***\n")
263 print("DataFrame[DataFrame[列名].str.len() >= 3]\n")
264 result = df商品一覧[df商品一覧['商品名'].str.len() >= 3]
265 print(result)
商品名が3文字以上のデータを取り出す
264行目で、条件式を df商品一覧['商品名'].str.len() >= 3 としています。
267 # 商品名の先頭が"み"で始まるデータを取り出す(str.startswith)
268 print("\n*** 商品名の先頭が'み'で始まるデータを取り出す(str.startswith)***\n")
269 print("DataFrame[DataFrame[列名].str.startswith('み')]\n")
270 result = df商品一覧[df商品一覧['商品名'].str.startswith('み')]
271 print(result)
商品名の先頭が"み"で始まるデータを取り出す
270行目で、条件式を df商品一覧['商品名'].str.startswith('み') としています。
273 # 商品名に"ン"を含むデータを取り出す(str.contains)
274 print("\n*** 商品名に'ン'を含むデータを取り出す(str.contains)***\n")
275 print("DataFrame[DataFrame[列名].str.contains('ン')]\n")
276 result = df商品一覧[df商品一覧['商品名'].str.contains('ン')]
277 print(result)
278
279 #終了9
280 #sys.exit()
商品名に"ン"を含むデータを取り出す
276行目で、条件式を df商品一覧['商品名'].str.contains('ン') としています。
5.queryを使ったデータの絞り込み
① 数値条件を指定したデータの絞り込み
DataFrame.query(条件文字列)を使うと、絞り込み条件を容易かつ直感的に書くことができます。
ソースコード #終了9 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # DataFrame.queryを使ったデータの絞り込み # 解説: DataFrame.query(条件文字列) 商品コード 商品名 単価 産地 0 A0001 みかん 100 和歌山 1 A0002 メロン 200 茨城県 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 4 A0005 バナナ 500 沖縄県 (行数:5、列数:4) *** 単価が 200 より大きくて 500 より小さなデータを取り出す(and条件)*** 商品コード 商品名 単価 産地 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 *** 単価が 200 より大きくて 500 より小さなデータを取り出す(比較演算子の連結)*** 商品コード 商品名 単価 産地 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 *** 条件文字列の中で変数を使用する *** 商品コード 商品名 単価 産地 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 4 A0005 バナナ 500 沖縄県
DataFrame.query(条件文字列)
プログラムソースを確認します。
300 print("\n*** 単価が 200 より大きくて 500 より小さなデータを取り出す(and条件)***\n")
301 result = df商品一覧.query('単価 > 200 and 単価 < 500')
302 print(result)
単価が 200 より大きくて 500 より小さなデータを取り出す(and条件)
301行目で、条件文字列を '単価 > 200 and 単価 < 500' としています。
304 print("\n*** 単価が 200 より大きくて 500 より小さなデータを取り出す(比較演算子の連結)***\n")
305 result = df商品一覧.query('200 < 単価 < 500')
306 print(result)
単価が 200 より大きくて 500 より小さなデータを取り出す(比較演算子の連結)
305行目で、条件文字列を '200 < 単価 < 500' としています。
'200 < 単価 and 単価 < 500' と書くのと同じです。
308 print("\n*** 条件文字列の中で変数を使用する ***\n")
309 val = 200
310 result = df商品一覧.query('単価 > @val')
311 print(result)
312
313 #終了10
314 #sys.exit()
条件文字列の中で変数を使用する
309行目で、変数 val に 200 をセットしています。
310行目のとおり、条件文字列の中で変数 val を使用する場合は、"@" を付けて @val にします。
② 文字条件を指定したデータの絞り込み
ソースコード #終了10 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 商品名が3文字以上のデータを取り出す(str.len)*** 商品コード 商品名 単価 産地 0 A0001 みかん 100 和歌山 1 A0002 メロン 200 茨城県 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 4 A0005 バナナ 500 沖縄県 *** 商品名の先頭が'み'で始まるデータを取り出す(str.startswith)*** 商品コード 商品名 単価 産地 0 A0001 みかん 100 和歌山 *** 商品名に'ン'を含むデータを取り出す(str.contains)*** 商品コード 商品名 単価 産地 1 A0002 メロン 200 茨城県 2 A0003 レモン 300 広島県
DataFrame.query(条件文字列)
プログラムソースを確認します。
317 # 商品名が3文字以上のデータを取り出す(str.len)
318 print("\n*** 商品名が3文字以上のデータを取り出す(str.len)***\n")
319 result = df商品一覧.query('商品名.str.len() >= 3')
320 print(result)
商品名が3文字以上のデータを取り出す
319行目で、条件文字列を '商品名.str.len() >= 3' としています。
322 # 商品名の先頭が"み"で始まるデータを取り出す(str.startswith)
323 print("\n*** 商品名の先頭が'み'で始まるデータを取り出す(str.startswith)***\n")
324 result = df商品一覧.query('商品名.str.startswith("み")')
325 print(result)
商品名の先頭が"み"で始まるデータを取り出す
324行目で、条件文字列を '商品名.str.startswith("み")' としています。
327 # 商品名に"ン"を含むデータを取り出す(str.contains)
328 print("\n*** 商品名に'ン'を含むデータを取り出す(str.contains)***\n")
329 result = df商品一覧.query('商品名.str.contains("ン")')
330 print(result)
331
332 #終了11
333 #sys.exit()
商品名に"ン"を含むデータを取り出す
329行目で、条件文字列を '商品名.str.contains("ン")' としています。
6.列の追加
① 新しい列の追加
ソースコード #終了11 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # 新しい列の追加 # 商品コード 商品名 単価 産地 0 A0001 みかん 100 和歌山 1 A0002 メロン 200 茨城県 2 A0003 レモン 300 広島県 3 A0004 りんご 400 青森県 4 A0005 バナナ 500 沖縄県 (行数:5、列数:4) *** 原価の列を追加 *** 商品コード 商品名 単価 産地 原価 0 A0001 みかん 100 和歌山 50 1 A0002 メロン 200 茨城県 120 2 A0003 レモン 300 広島県 210 3 A0004 りんご 400 青森県 320 4 A0005 バナナ 500 沖縄県 450 (行数:5、列数:5) *** 既存の列を使って新しい列を追加 *** 商品コード 商品名 単価 産地 原価 メッセージ 0 A0001 みかん 100 和歌山 50 みかんは100円です 1 A0002 メロン 200 茨城県 120 メロンは200円です 2 A0003 レモン 300 広島県 210 レモンは300円です 3 A0004 りんご 400 青森県 320 りんごは400円です 4 A0005 バナナ 500 沖縄県 450 バナナは500円です (行数:5、列数:6) *** 空の列を追加 *** 商品コード 商品名 単価 産地 原価 メッセージ 空の列 0 A0001 みかん 100 和歌山 50 みかんは100円です 1 A0002 メロン 200 茨城県 120 メロンは200円です 2 A0003 レモン 300 広島県 210 レモンは300円です 3 A0004 りんご 400 青森県 320 りんごは400円です 4 A0005 バナナ 500 沖縄県 450 バナナは500円です (行数:5、列数:7) *** 列名の変更('空の列'から'備考'へ)*** 商品コード 商品名 単価 産地 原価 メッセージ 備考 0 A0001 みかん 100 和歌山 50 みかんは100円です 1 A0002 メロン 200 茨城県 120 メロンは200円です 2 A0003 レモン 300 広島県 210 レモンは300円です 3 A0004 りんご 400 青森県 320 りんごは400円です 4 A0005 バナナ 500 沖縄県 450 バナナは500円です (行数:5、列数:7)
プログラムソースを確認します。
351 # 原価の列を追加
352 print("\n*** 原価の列を追加 ***\n")
353 df商品一覧['原価'] = [50, 120, 210, 320, 450]
原価の列を追加
353行目で、原価の列に入れる数値のリスト [50, 120, 210, 320, 450] を使って、新たに 原価 の列を追加しています。
358 # 既存の列を使って新しい列を追加
359 print("\n*** 既存の列を使って新しい列を追加 ***\n")
360 df商品一覧['メッセージ'] = (df商品一覧['商品名'] + "は" + df商品一覧['単価'].astype(str) + "円です")
既存の列を使って新しい列を追加
360行目で、商品名 と 単価 のデータを組み合わせて文字列を作り、その文字列をデータとする メッセージ の列を追加しています。
365 # 空の列を追加
366 print("\n*** 空の列を追加 ***\n")
367 df商品一覧['空の列'] = ""
空の列を追加
367行目で、列名を 空の列、データを空文字で新たな列を追加しています。
372 # 列名の変更
373 print("\n*** 列名の変更('空の列'から'備考'へ)***\n")
374 df商品一覧.rename(columns = {'空の列':'備考'}, inplace = True)
375
379 #終了12
380 #sys.exit()
列名の変更
374行目で、rename() を使って、空の列 の列名を 備考 に変更しています。
columns引数に、変更前と変更後の列名を辞書で設定します。
inplace引数に、True を指定すると、列名の変更が反映されます。
7.データの変更
① データを変更する
ソースコード #終了12 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
# # データの変更 # 商品コード 商品名 単価 産地 原価 メッセージ 備考 0 A0001 みかん 100 和歌山 50 みかんは100円です 1 A0002 メロン 200 茨城県 120 メロンは200円です 2 A0003 レモン 300 広島県 210 レモンは300円です 3 A0004 りんご 400 青森県 320 りんごは400円です 4 A0005 バナナ 500 沖縄県 450 バナナは500円です (行数:5、列数:7) *** 備考の列データを変更 *** 商品コード 商品名 単価 産地 原価 メッセージ 備考 0 A0001 みかん 100 和歌山 50 みかんは100円です 新規商品 1 A0002 メロン 200 茨城県 120 メロンは200円です 在庫なし 2 A0003 レモン 300 広島県 210 レモンは300円です 販売休止 3 A0004 りんご 400 青森県 320 りんごは400円です 入荷未定 4 A0005 バナナ 500 沖縄県 450 バナナは500円です 季節商品 (行数:5、列数:7) *** インデックス 4 (バナナ)の単価を 600 に変更 *** 商品コード 商品名 単価 産地 原価 メッセージ 備考 0 A0001 みかん 100 和歌山 50 みかんは100円です 新規商品 1 A0002 メロン 200 茨城県 120 メロンは200円です 在庫なし 2 A0003 レモン 300 広島県 210 レモンは300円です 販売休止 3 A0004 りんご 400 青森県 320 りんごは400円です 入荷未定 4 A0005 バナナ 600 沖縄県 450 バナナは500円です 季節商品 (行数:5、列数:7)
プログラムソースを確認します。
398 # 備考の列データを変更
399 print("\n*** 備考の列データを変更 ***\n")
400 df商品一覧['備考'] = ["新規商品", "在庫なし", "販売休止", "入荷未定", "季節商品"]
備考の列データを変更
400行目で、変更するデータのリストを使って、備考 の列を変更しています。
405 # インデックス 4 の商品コードを変更
406 print("\n*** インデックス 4 (バナナ)の単価を 600 に変更 ***\n")
407 df商品一覧.loc[4, '単価'] = 600
408
412 #終了13
413 #sys.exit()
インデックス 4 の商品コードを変更
407行目で、loc[行の指定, 列の指定] を使って、行の指定 を インデックス 4、列の指定 を 単価 で変更箇所を設定して、値 600 をセットしています。
② ループ文を使って1行ずつ処理する
ソースコード #終了13 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** ループ文を使ってメッセージの列データを変更 *** 商品コード 商品名 単価 産地 原価 メッセージ 備考 0 A0001 みかん 100 和歌山 50 みかんの産地は和歌山です 新規商品 1 A0002 メロン 200 茨城県 120 メロンの産地は茨城県です 在庫なし 2 A0003 レモン 300 広島県 210 レモンの産地は広島県です 販売休止 3 A0004 りんご 400 青森県 320 りんごの産地は青森県です 入荷未定 4 A0005 バナナ 600 沖縄県 450 バナナの産地は沖縄県です 季節商品 (行数:5、列数:7)
プログラムソースを確認します。
416 # ループ文を使って1行ずつ処理する
417 print("\n*** ループ文を使ってメッセージの列データを変更 ***\n")
418 for index, data in df商品一覧.iterrows():
419 str商品名 = data['商品名']
420 str産地 = data['産地']
421 df商品一覧.loc[index, 'メッセージ'] = str商品名 + "の産地は" + str産地 + "です"
422
426 #終了14
427 #sys.exit()
418行目の for文で、DataFrame(df商品一覧)の行データを1行ずつ処理していきます。
変数index には、インデックスの値、data変数 には1行分のデータが格納されます。
419行目で、商品名のデータを取得しています。
420行目で、産地のデータを取得しています。
421行目で、loc[行の指定, 列の指定] を使って、行の指定 を 変数index、列の指定 を メッセージ で変更箇所を設定して、商品名と産地を組み合わせた文字列をセットしています。
8.DataFrameの結合(横方向)
① ExcelファイルからDataFrameを作成
販売実績.xlsx と 商品一覧.xlsx から DataFrameを作成します。
ソースコード #終了14 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
販売実績ファイル名:C:\Python\販売実績.xlsx
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0002 3
2 202511 A0003 4
3 202511 A0007 2
4 202511 A0010 2
5 202512 A0001 4
6 202512 A0003 2
7 202512 A0004 1
8 202512 A0005 3
9 202512 A0006 5
10 202601 A0008 5
11 202601 A0010 1
12 202601 A0005 4
13 202601 A9999 3
14 202601 A0001 2
(行数:15、列数:3)
商品一覧ファイル名:C:\Python\商品一覧.xlsx
商品コード 商品名 単価 産地
0 A0001 みかん 100 和歌山
1 A0002 メロン 200 茨城県
2 A0003 レモン 300 広島県
3 A0004 りんご 400
4 A0005 バナナ 500 沖縄県
5 A0006 ぶどう 600 千葉県
6 A0007 スイカ 700 熊本県
7 A0008 イチゴ 800 栃木県
8 A0009 カシス 900
9 A0010 ライム 1000
(行数:10、列数:4)
この2つの DataFrame を横方向に結合していきます。
プログラムソースを確認します。
441 # 販売実績ファイルの読み込み
442 filename = dirHome + r"\販売実績.xlsx"
443 print("\n販売実績ファイル名:" + filename)
444
445 # DataFrameを作成
446 df販売実績 = pd.read_excel(filename, sheet_name = 'Sheet1', dtype = object)
447
448 print(df販売実績)
449 print("(行数:" + str(df販売実績.shape[0]) + "、列数:" + str(df販売実績.shape[1]) + ")")
450
451
452 # 商品一覧ファイルの読み込み
453 filename = dirHome + r"\商品一覧.xlsx"
454 print("\n商品一覧ファイル名:" + filename)
455
456 # DataFrameを作成
457 df商品一覧 = pd.read_excel(filename, sheet_name = 'Sheet3', dtype = object)
458
459 # 欠損値を空文字で埋める
460 df商品一覧 = df商品一覧.fillna("")
461
462 print(df商品一覧)
463 print("(行数:" + str(df商品一覧.shape[0]) + "、列数:" + str(df商品一覧.shape[1]) + ")")
464
465 #終了15
466 #sys.exit()
② 左外部結合(how = 'left')
ソースコード #終了15 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 商品コードをキーにして左外部結合(how = 'left')***
年月 商品コード 数量 商品名 単価 産地
0 202511 A0001 8 みかん 100 和歌山
1 202511 A0002 3 メロン 200 茨城県
2 202511 A0003 4 レモン 300 広島県
3 202511 A0007 2 スイカ 700 熊本県
4 202511 A0010 2 ライム 1000
5 202512 A0001 4 みかん 100 和歌山
6 202512 A0003 2 レモン 300 広島県
7 202512 A0004 1 りんご 400
8 202512 A0005 3 バナナ 500 沖縄県
9 202512 A0006 5 ぶどう 600 千葉県
10 202601 A0008 5 イチゴ 800 栃木県
11 202601 A0010 1 ライム 1000
12 202601 A0005 4 バナナ 500 沖縄県
13 202601 A9999 3 NaN NaN NaN
14 202601 A0001 2 みかん 100 和歌山
解説:
販売実績のデータは結合相手の商品一覧に存在しなくても表示されます。(商品コードが A9999 のデータ)
販売実績を主として結合します。
販売実績のデータは、結合相手の商品一覧に存在しなくても表示されます。(商品コードが A9999 のデータ)
プログラムソースを確認します。
469 # 商品コードをキーにして左外部結合(how = 'left')
470 print("\n*** 商品コードをキーにして左外部結合(how = 'left')***\n")
471 df左結合 = pd.merge(df販売実績, df商品一覧, on = '商品コード', how = 'left')
472
473 print(df左結合)
474
475 print("\n解説:")
476 print("販売実績のデータは結合相手の商品一覧に存在しなくても表示されます。(商品コードが A9999 のデータ)")
477
478 #終了16
479 #sys.exit()
471行目の merge() を使って、販売実績を主として商品一覧と結合しています。
on引数 に結合のキーとする列名を指定します。
③ 右外部結合(how = 'right')
ソースコード #終了16 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 商品コードをキーにして右外部結合(how = 'right')***
商品コード 商品名 単価 産地 年月 数量
0 A0001 みかん 100 和歌山 202511 8
1 A0001 みかん 100 和歌山 202512 4
2 A0001 みかん 100 和歌山 202601 2
3 A0002 メロン 200 茨城県 202511 3
4 A0003 レモン 300 広島県 202511 4
5 A0003 レモン 300 広島県 202512 2
6 A0004 りんご 400 202512 1
7 A0005 バナナ 500 沖縄県 202512 3
8 A0005 バナナ 500 沖縄県 202601 4
9 A0006 ぶどう 600 千葉県 202512 5
10 A0007 スイカ 700 熊本県 202511 2
11 A0008 イチゴ 800 栃木県 202601 5
12 A0009 カシス 900 NaN NaN
13 A0010 ライム 1000 202511 2
14 A0010 ライム 1000 202601 1
解説:
商品一覧のデータは結合相手の販売実績に存在しなくても表示されます。(商品コードが A0009 のデータ)
商品一覧を主として結合します。
商品一覧のデータは、結合相手の販売実績に存在しなくても表示されます。(商品コードが A0009 のデータ)
プログラムソースを確認します。
482 # 商品コードをキーにして右外部結合(how = 'right')
483 print("\n*** 商品コードをキーにして右外部結合(how = 'right')***\n")
484 df右結合 = pd.merge(df販売実績, df商品一覧, on = '商品コード', how = 'right')
485
486 # 列の並べ替え
487 df右結合 = df右結合[['商品コード','商品名','単価','産地','年月','数量']]
488
489 print(df右結合)
490
491 print("\n解説:")
492 print("商品一覧のデータは結合相手の販売実績に存在しなくても表示されます。(商品コードが A0009 のデータ)")
493
494 #終了17
495 #sys.exit()
484行目の merge() を使って、商品一覧を主として販売実績と結合しています。
on引数 に結合のキーとする列名を指定します。
④ 完全結合(how = 'outer')
ソースコード #終了17 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 商品コードをキーにして完全結合(how = 'outer')***
年月 商品コード 数量 商品名 単価 産地
0 202511 A0001 8 みかん 100 和歌山
1 202512 A0001 4 みかん 100 和歌山
2 202601 A0001 2 みかん 100 和歌山
3 202511 A0002 3 メロン 200 茨城県
4 202511 A0003 4 レモン 300 広島県
5 202512 A0003 2 レモン 300 広島県
6 202512 A0004 1 りんご 400
7 202512 A0005 3 バナナ 500 沖縄県
8 202601 A0005 4 バナナ 500 沖縄県
9 202512 A0006 5 ぶどう 600 千葉県
10 202511 A0007 2 スイカ 700 熊本県
11 202601 A0008 5 イチゴ 800 栃木県
12 NaN A0009 NaN カシス 900
13 202511 A0010 2 ライム 1000
14 202601 A0010 1 ライム 1000
15 202601 A9999 3 NaN NaN NaN
解説:
販売実績、商品一覧ともに、結合相手が存在しなくても表示されます。
販売実績、商品一覧ともに、結合相手が存在しなくても表示されます。
販売実績にあって、商品一覧にないデータ:商品コードが A9999 のデータ
商品一覧にあって、販売実績にないデータ:商品コードが A0009 のデータ
プログラムソースを確認します。
498 # 商品コードをキーにして完全結合(how = 'outer')
499 print("\n*** 商品コードをキーにして完全結合(how = 'outer')***\n")
500 df完全結合 = pd.merge(df販売実績, df商品一覧, on = '商品コード', how = 'outer')
501
502 print(df完全結合)
503
504 print("\n解説:")
505 print("販売実績、商品一覧ともに、結合相手が存在しなくても表示されます。")
506
507 #終了18
508 #sys.exit()
500行目の merge() を使って、商品一覧と販売実績を完全結合しています。
on引数 に結合のキーとする列名を指定します。
9.データの削除
① 行データの削除
ソースコード #終了18 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
#
# データの削除
#
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0002 3
2 202511 A0003 4
3 202511 A0007 2
4 202511 A0010 2
5 202512 A0001 4
6 202512 A0003 2
7 202512 A0004 1
8 202512 A0005 3
9 202512 A0006 5
10 202601 A0008 5
11 202601 A0010 1
12 202601 A0005 4
13 202601 A9999 3
14 202601 A0001 2
(行数:15、列数:3)
*** インデックス 13 の行データを削除 ***
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0002 3
2 202511 A0003 4
3 202511 A0007 2
4 202511 A0010 2
5 202512 A0001 4
6 202512 A0003 2
7 202512 A0004 1
8 202512 A0005 3
9 202512 A0006 5
10 202601 A0008 5
11 202601 A0010 1
12 202601 A0005 4
14 202601 A0001 2
(行数:14、列数:3)
プログラムソースを確認します。
526 # 行データの削除
527 print("\n*** インデックス 13 の行データを削除 ***\n")
528 df販売実績 = df販売実績.drop(13)
529
533 #終了19
534 #sys.exit()
インデックス 13 の行データを削除
528行目で、drop()を使い 引数に インデックス 13 を指定して行データを削除しています。
② 列データの削除
ソースコード #終了19 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
商品コード 商品名 単価 産地 0 A0001 みかん 100 和歌山 1 A0002 メロン 200 茨城県 2 A0003 レモン 300 広島県 3 A0004 りんご 400 4 A0005 バナナ 500 沖縄県 5 A0006 ぶどう 600 千葉県 6 A0007 スイカ 700 熊本県 7 A0008 イチゴ 800 栃木県 8 A0009 カシス 900 9 A0010 ライム 1000 (行数:10、列数:4) *** 産地の列を削除 *** 商品コード 商品名 単価 0 A0001 みかん 100 1 A0002 メロン 200 2 A0003 レモン 300 3 A0004 りんご 400 4 A0005 バナナ 500 5 A0006 ぶどう 600 6 A0007 スイカ 700 7 A0008 イチゴ 800 8 A0009 カシス 900 9 A0010 ライム 1000 (行数:14、列数:3)
産地の列を削除しました。
プログラムソースを確認します。
537 print("\n")
538 print(df商品一覧)
539 print("(行数:" + str(df商品一覧.shape[0]) + "、列数:" + str(df商品一覧.shape[1]) + ")")
540
541 # 列データの削除
542 print("\n*** 産地の列を削除 ***\n")
543 df商品一覧 = df商品一覧.drop('産地', axis = 1)
544
548 #終了20
549 #sys.exit()
産地の列を削除
543行目で、drop()を使い 引数に 列名 '産地' を指定して列データを削除しています。
列データを削除するときは、axis = 1 にします。
10.その他のデータ削除の方法
① 重複データの削除
ソースコード #終了20 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
#
# その他のデータ削除の方法
#
*** 重複データの削除 ***
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8 ← 重複しているデータ
2 202511 A0002 4
3 202511 B0003 2
4 202511 B0004 2
5 202512 A0001 4
6 202512 A0001 4 ← 重複しているデータ
7 202512 A0002 1
8 202512 A0002 3
9 202512 B0003 5
(行数:10、列数:3)
DataFrame.drop_duplicates()
年月 商品コード 数量
0 202511 A0001 8
2 202511 A0002 4
3 202511 B0003 2
4 202511 B0004 2
5 202512 A0001 4
7 202512 A0002 1
8 202512 A0002 3
9 202512 B0003 5
(行数:8、列数:3)
解説:
年月、商品コード、数量が同じデータが削除されました(インデックス:1, 6)
インデックスを連番に振り直し
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0002 4
2 202511 B0003 2
3 202511 B0004 2
4 202512 A0001 4
5 202512 A0002 1
6 202512 A0002 3
7 202512 B0003 5
(行数:8、列数:3)
プログラムソースを確認します。
567 # 重複データの削除
568 print("\n*** 重複データの削除 ***\n")
569
570 print(df販売実績)
571 print("(行数:" + str(df販売実績.shape[0]) + "、列数:" + str(df販売実績.shape[1]) + ")")
572
573 print("\nDataFrame.drop_duplicates()\n")
574 result = df販売実績.drop_duplicates()
575
576 print(result)
577 print("(行数:" + str(result.shape[0]) + "、列数:" + str(result.shape[1]) + ")")
578
579 print("\n解説:")
580 print("年月、商品コード、数量が同じデータが削除されました(インデックス:1, 6)")
581
582 print("\nインデックスを連番に振り直し\n")
583 result = result.reset_index(drop = True)
584
588 #終了21
589 #sys.exit()
574行目の drop_duplicates() を使って、すべての列のデータ(年月、商品コード、数量)が同じデータ(重複データ)を削除しています。(インデックス:1, 6 のデータ)
583行目の reset_index(drop = True) を使って、インデックスを連番に振り直しています。
② 重複データの削除(列を指定)
ソースコード #終了21 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 年月と商品コードを指定して重複を削除 ***
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8 ← 年月と商品コードで重複しているデータ
2 202511 A0002 4
3 202511 B0003 2
4 202511 B0004 2
5 202512 A0001 4
6 202512 A0001 4 ← 年月と商品コードで重複しているデータ
7 202512 A0002 1
8 202512 A0002 3 ← 年月と商品コードで重複しているデータ
9 202512 B0003 5
(行数:10、列数:3)
DataFrame.drop_duplicates(subset = 列のリスト, keep)
年月 商品コード 数量
0 202511 A0001 8
2 202511 A0002 4
3 202511 B0003 2
4 202511 B0004 2
5 202512 A0001 4
7 202512 A0002 1
9 202512 B0003 5
(行数:7、列数:3)
解説:
年月と商品コードで重複を確認するので、数量が異なっていても削除されます。(インデックス:8)
keep = 'first' 重複した最初の行が残ります
keep = 'last' 重複した最後の行が残ります
keep = False 重複しているすべての行が削除されます
プログラムソースを確認します。
592 # 重複データの削除(列を指定)
593 print("\n*** 年月と商品コードを指定して重複を削除 ***\n")
594
595 print(df販売実績)
596 print("(行数:" + str(df販売実績.shape[0]) + "、列数:" + str(df販売実績.shape[1]) + ")")
597
598 print("\nDataFrame.drop_duplicates(subset = 列のリスト, keep)\n")
599 result = df販売実績.drop_duplicates(subset = ['年月', '商品コード'], keep = 'first')
600
610 #終了22
611 #sys.exit()
599行目の drop_duplicates() で重複データを削除しています。
subsetパラメータに、列名のリストを設定することで重複を確認する列を指定することができます。
keepパラメータは、以下の通りです。
keep = 'first' 重複した最初の行が残ります
keep = 'last' 重複した最後の行が残ります
keep = False 重複しているすべての行が削除されます
③ 数値条件を指定して削除
ソースコード #終了22 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 年月が202512のデータを削除 ***
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8
2 202511 A0002 4
3 202511 B0003 2
4 202511 B0004 2
5 202512 A0001 4
6 202512 A0001 4
7 202512 A0002 1
8 202512 A0002 3
9 202512 B0003 5
(行数:10、列数:3)
年月が202512のデータのインデックスを取得
Index([5, 6, 7, 8, 9], dtype='int64')
インデックスを指定して行削除
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8
2 202511 A0002 4
3 202511 B0003 2
4 202511 B0004 2
(行数:5、列数:3)
プログラムソースを確認します。
614 # 条件を指定して削除
615 print("\n*** 年月が202512のデータを削除 ***\n")
616
617 print(df販売実績)
618 print("(行数:" + str(df販売実績.shape[0]) + "、列数:" + str(df販売実績.shape[1]) + ")")
619
620 # 年月が202512のデータのインデックスを取得
621 print("\n年月が202512のデータのインデックスを取得")
622 インデックス = df販売実績.index[df販売実績['年月'] == 202512]
623 print(インデックス)
624
625 # インデックスを指定して行削除
626 print("\nインデックスを指定して行削除")
627 result = df販売実績.drop(インデックス)
628
629 print(result)
630 print("(行数:" + str(result.shape[0]) + "、列数:" + str(result.shape[1]) + ")")
631
632 #終了23
633 #sys.exit()
622行目で、年月が 202512 のデータのインデックスを取得しています。 [5, 6, 7, 8, 9]
627行目で、drop() に 取得したインデックスを指定し削除しています。
④ 文字条件を指定して削除
ソースコード #終了23 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 商品コードの先頭が'B'のデータを削除 ***
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8
2 202511 A0002 4
3 202511 B0003 2
4 202511 B0004 2
5 202512 A0001 4
6 202512 A0001 4
7 202512 A0002 1
8 202512 A0002 3
9 202512 B0003 5
(行数:10、列数:3)
先頭が'B'のデータのインデックスを取得
Index([3, 4, 9], dtype='int64')
インデックスを指定して行削除
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8
2 202511 A0002 4
5 202512 A0001 4
6 202512 A0001 4
7 202512 A0002 1
8 202512 A0002 3
(行数:7、列数:3)
プログラムソースを確認します。
636 # 条件を指定して削除
637 print("\n*** 商品コードの先頭が'B'のデータを削除 ***\n")
638
639 print(df販売実績)
640 print("(行数:" + str(df販売実績.shape[0]) + "、列数:" + str(df販売実績.shape[1]) + ")")
641
642 print("\n先頭が'B'のデータのインデックスを取得")
643 インデックス = df販売実績[df販売実績['商品コード'].str.startswith('B')].index
644 print(インデックス)
645
646 # インデックスを指定して行削除
647 print("\nインデックスを指定して行削除")
648 result = df販売実績.drop(インデックス)
649
650 print(result)
651 print("(行数:" + str(result.shape[0]) + "、列数:" + str(result.shape[1]) + ")")
652
653 #終了24
654 #sys.exit()
643行目で、商品コード の先頭が 'B' のデータのインデックスを取得しています。 [3, 4, 9]
648行目で、drop() に 取得したインデックスを指定し削除しています。
⑤ 抽出条件式で絞り込んで削除
ソースコード #終了24 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** DataFrame[抽出条件式](絞り込み)を使って、商品コードの先頭が'B'のデータを削除 ***
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8
2 202511 A0002 4
3 202511 B0003 2
4 202511 B0004 2
5 202512 A0001 4
6 202512 A0001 4
7 202512 A0002 1
8 202512 A0002 3
9 202512 B0003 5
(行数:10、列数:3)
先頭が'B'のデータで絞り込み df販売実績[先頭が'B']
年月 商品コード 数量
3 202511 B0003 2
4 202511 B0004 2
9 202512 B0003 5
(行数:3、列数:3)
先頭が'B'のデータでないもので絞り込み df販売実績[~先頭が'B']
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8
2 202511 A0002 4
5 202512 A0001 4
6 202512 A0001 4
7 202512 A0002 1
8 202512 A0002 3
(行数:7、列数:3)
解説:
先頭が'B'ではないデータで絞り込むことで、先頭が'B'のデータを削除したことと同じです。
条件の否定形を使って、データを削除します。
プログラムソースを確認します。
657 # DataFrame[抽出条件式](絞り込み)で削除
658 print("\n*** DataFrame[抽出条件式](絞り込み)を使って、商品コードの先頭が'B'のデータを削除 ***\n")
659
660 print(df販売実績)
661 print("(行数:" + str(df販売実績.shape[0]) + "、列数:" + str(df販売実績.shape[1]) + ")")
662
663 # 商品コードの先頭が'B'のデータを抽出条件
664 sri抽出条件 = df販売実績['商品コード'].str.startswith('B')
665
666 # 抽出条件で絞り込み
667 print("\n先頭が'B'のデータで絞り込み df販売実績[先頭が'B']\n")
668 result = df販売実績[sri抽出条件]
669
670 print(result)
671 print("(行数:" + str(result.shape[0]) + "、列数:" + str(result.shape[1]) + ")")
672
673 # 抽出条件でないもので絞り込み(抽出条件の否定で絞り込み)
674 print("\n先頭が'B'のデータでないもので絞り込み df販売実績[~先頭が'B']\n")
675 result = df販売実績[~sri抽出条件] # 『~』抽出条件の否定
676
677 print(result)
678 print("(行数:" + str(result.shape[0]) + "、列数:" + str(result.shape[1]) + ")")
679
680 print("\n解説:")
681 print("先頭が'B'ではないデータで絞り込むことで、先頭が'B'のデータを削除したことと同じです。")
682
683 #終了25
684 #sys.exit()
664行目で 商品コード の先頭が'B'のデータを抽出して、668行目でDataFrame(df販売実績)を抽出したもので絞り込んでいます。
675行目で 抽出したもの以外(抽出条件の否定形)で絞り込むと、先頭が'B'のデータを削除したことと同じになります。
⑥ ループ文を使って削除
ソースコード #終了25 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** ループ文を使って'商品コード'の先頭が'B'のデータを削除 ***
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8
2 202511 A0002 4
3 202511 B0003 2
4 202511 B0004 2
5 202512 A0001 4
6 202512 A0001 4
7 202512 A0002 1
8 202512 A0002 3
9 202512 B0003 5
(行数:10、列数:3)
ループ文を使って1行毎に処理する
削除対象インデックス:3
削除対象インデックス:4
削除対象インデックス:9
年月 商品コード 数量
0 202511 A0001 8
1 202511 A0001 8
2 202511 A0002 4
5 202512 A0001 4
6 202512 A0001 4
7 202512 A0002 1
8 202512 A0002 3
(行数:7、列数:3)
プログラムソースを確認します。
687 # ループ文を使って'商品コード'の先頭が'B'のデータを削除
688 print("\n*** ループ文を使って'商品コード'の先頭が'B'のデータを削除 ***\n")
689
690 print(df販売実績)
691 print("(行数:" + str(df販売実績.shape[0]) + "、列数:" + str(df販売実績.shape[1]) + ")")
692
693 # データフレームのコピー
694 df結果 = df販売実績.copy(deep = True)
695
696 # ループ文を使って1行毎に処理する
697 print("\nループ文を使って1行毎に処理する")
698 for index, data in df結果.iterrows():
699 str商品コード = str(data['商品コード'])
700 if str商品コード.startswith('B'):
701 print("削除対象インデックス:" + str(index))
702 df結果 = df結果.drop(index)
703
704 print("")
705 print(df結果)
706 print("(行数:" + str(df結果.shape[0]) + "、列数:" + str(df結果.shape[1]) + ")")
707
708 #終了26
709 #sys.exit()
694行目で、df販売実績 をコピーして、df結果 を作成しています。
698行目の for文で、DataFrame(df結果)の行データを1行ずつ処理していきます。
変数index には、インデックスの値、data変数 には1行分のデータが格納されます。
699行目で、商品コードのデータを取得しています。
700行目で、商品コード'の先頭が'B'かを判断しています。 変数index が [3, 4, 9]
702行目で、drop()を使い 引数に 変数index を指定して行データを削除しています。
⑦ 全行を削除
ソースコード #終了26 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** 全行を削除 *** Empty DataFrame Columns: [年月, 商品コード, 数量] Index: [] (行数:0、列数:3)
プログラムソースを確認します。
712 # 全行を削除
713 print("\n*** 全行を削除 ***\n")
714 df全行削除 = df販売実績.iloc[:0]
715
716 print(df全行削除)
717 print("(行数:" + str(df全行削除.shape[0]) + "、列数:" + str(df全行削除.shape[1]) + ")")
718
719 sys.exit()
714行目で、iloc[] の行の指定で、ひとつの行も選択しないスライスを指定しています。 iloc[:0]
| <Pandas_DataFrameの基礎 | Pandas.DataFrameの利用 | Pandas.DataFrameでデータ集計> |

