
PythonでCSVファイルを読み書きする方法を、演習用プログラムのソースコードを使い、それを実行しながら解説します。
1.pandasライブラリのインストール
本章の最後で、pandasライブラリの紹介をします。
pandas とは、データ解析を容易にする機能を提供するPythonのデータ解析ライブラリです。
CSVファイルや、Excelファイルのような表形式データを扱うときにもとても便利なライブラリです。
pandas を使うには、事前にインストール作業が必要です。
手順を追って説明します。
① コマンドプロンプトを管理者として実行
Windows画面の左下にある検索ボックスに、キーボードから cmd と入力します。
右上に コマンドプロンプト が表示されていることを確認して、『管理者として実行』をクリックします。
コマンドプロンプトを管理者として実行
ユーザー アカウント制御 ダイアログボックスが表示されて、「このアプリがデバイスに変更を加えることを許可しますか?」と聞いてくるので、『はい』をクリックします。
管理者:コマンドプロンプト が起動します。
Microsoft Windows [Version 10.0.22631.4317] (c) Microsoft Corporation. All rights reserved. C:\Windows\System32>
② インストールされているライブラリの確認
管理者:コマンドプロンプト でキーボードから pip list と入力して、 Enter キーを押下します。
インストールされているライブラリの一覧が表示されます。
pandas がインストールされていないことを確認します。
Microsoft Windows [Version 10.0.22631.4317] (c) Microsoft Corporation. All rights reserved. C:\Windows\System32>pip list Package Version ------- ------- pip 24.2 pywin32 307 C:\Windows\System32>
③ pandas のインストール
管理者:コマンドプロンプト でキーボードから pip install pandas と入力して、 Enter キーを押下します。
インストールには少々時間がかかります。
最後の行に『 Successfully installed 』と表示されれば、インストール完了です。
C:\Windows\System32>pip install pandas Collecting pandas Downloading pandas-2.2.3-cp312-cp312-win_amd64.whl.metadata (19 kB) Collecting numpy>=1.26.0 (from pandas) Using cached numpy-2.1.2-cp312-cp312-win_amd64.whl.metadata (59 kB) Collecting python-dateutil>=2.8.2 (from pandas) Using cached python_dateutil-2.9.0.post0-py2.py3-none-any.whl.metadata (8.4 kB) Collecting pytz>=2020.1 (from pandas) Using cached pytz-2024.2-py2.py3-none-any.whl.metadata (22 kB) Collecting tzdata>=2022.7 (from pandas) Downloading tzdata-2024.2-py2.py3-none-any.whl.metadata (1.4 kB) Collecting six>=1.5 (from python-dateutil>=2.8.2->pandas) Using cached six-1.16.0-py2.py3-none-any.whl.metadata (1.8 kB) Downloading pandas-2.2.3-cp312-cp312-win_amd64.whl (11.5 MB) ---------------------------------------- 11.5/11.5 MB 1.4 MB/s eta 0:00:00 Using cached numpy-2.1.2-cp312-cp312-win_amd64.whl (12.6 MB) Using cached python_dateutil-2.9.0.post0-py2.py3-none-any.whl (229 kB) Using cached pytz-2024.2-py2.py3-none-any.whl (508 kB) Downloading tzdata-2024.2-py2.py3-none-any.whl (346 kB) Using cached six-1.16.0-py2.py3-none-any.whl (11 kB) Installing collected packages: pytz, tzdata, six, numpy, python-dateutil, pandas Successfully installed numpy-2.1.2 pandas-2.2.3 python-dateutil-2.9.0.post0 pytz-2024.2 six-1.16.0 tzdata-2024.2 C:\Windows\System32>
【補足】学校や会社内のパソコンをお使いの方へ
pip install pandas が失敗する場合があります。
この場合は、インストールする際にプロキシサーバーの情報を渡す必要があります
プロキシサーバーの情報は、システム管理者に確認してください。
・プロキシサーバー名
・ポート番号
プロキシサーバーの情報を取得できましたら、pandas のインストールは次のようにします。
pip install --proxy="プロキシサーバー名:ポート番号" pandas
④ pandas のインストールの確認
管理者:コマンドプロンプト でキーボードから pip list と入力して、 Enter キーを押下します。
インストールされているライブラリの一覧が表示されます。
一覧に pandas があることを確認します。
C:\Windows\System32>pip list Package Version --------------- ----------- numpy 2.1.2 pandas 2.2.3 pip 24.2 python-dateutil 2.9.0.post0 pytz 2024.2 pywin32 307 six 1.16.0 tzdata 2024.2 C:\Windows\System32>
2.演習用プログラムのダウンロード
演習用プログラム( practice14.py )とCSVファイル( csv_file1.csv )をダウンロードします。
演習用プログラムは テキストファイルになっているので、エクスプローラーを使って拡張子を .txt から .py に変更します。
practice14.py、csv_file1.csv を Python をインストールしたフォルダ(今回は C:\Python)に置きます。
3.ソースコードの表示
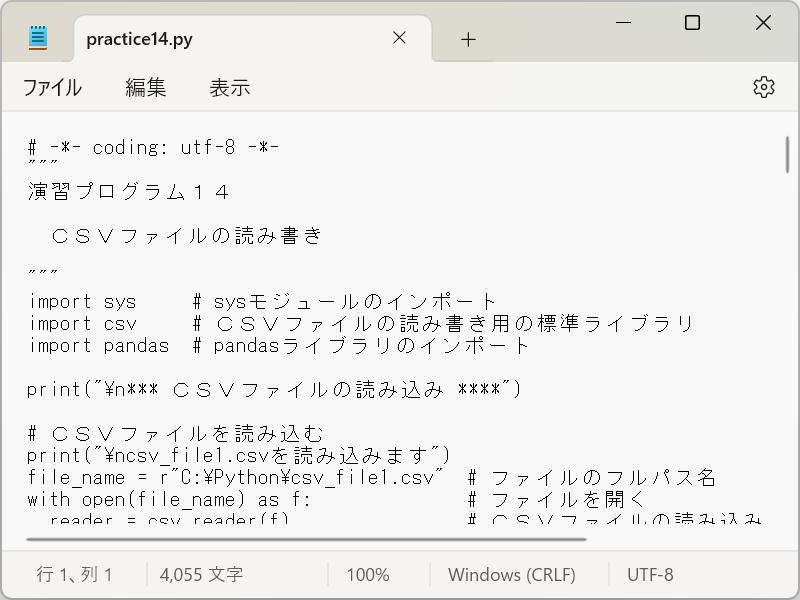
メモ帳を使って、演習用プログラム( practice14.py )を開きます。
practice14.py
4.CSVファイルの読み込み
最初にCSVファイルを読み込む方法を見ていきます。
① CSVファイルを読み込む
まずは、コマンドプロンプト で practice14.py を実行します。
プログラムを実行する方法は、こちらの記事『ファイルに保存されたプログラムの実行』を参照します。
以下のように表示されます。
C:\Users\kotablog>python C:\Python\practice14.py *** CSVファイルの読み込み **** csv_file1.csvを読み込みます ['商品コード', '商品名', '金額'] ['A0001', 'みかん', '100'] ['A0002', 'メロン', '200'] ['A0003', 'いちご', '300'] ['A0004', 'バナナ', '400'] ['A0005', 'トマト', '500']
プログラムソースを確認します。
01 # -*- coding: utf-8 -*-
02 """
03 演習プログラム14
04
05 CSVファイルの読み書き
06
07 """
08 import sys # sysモジュールのインポート
09 import csv # CSVファイルの読み書き用の標準ライブラリ
10 import pandas # pandasライブラリのインポート
11
12 print("\n*** CSVファイルの読み込み ****")
13
14 # CSVファイルを読み込む
15 print("\ncsv_file1.csvを読み込みます")
16 file_name = r"C:\Python\csv_file1.csv" # ファイルのフルパス名
17 with open(file_name) as f: # ファイルを開く
18 reader = csv.reader(f) # CSVファイルの読み込み
19 for row in reader: # 行ごとのデータをリストで取得
20 print(row) # 1行のデータを表示
21
22 #終了1
23 sys.exit()
09行目で CSVファイルを読み書きするための標準ライブラリをインポートしています。
10行目で 先ほどインストールした pandasライブラリをインポートしています。
16行目で変数 file_name に csv_file1.csv のフルパスファイル名をセットしています。
17行目で with文を使って、CSVファイルを開いています。
18行目で reader()メソッドを使ってCSVファイルを読み込み、reader オブジェクトに格納しています。
19行目の for文を使って、行ごとにデータを取り出しています。
20行目で 行のデータ(リスト)を表示しています。
② 2次元リスト(リストのリスト)として取得
ソースコード #終了1 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
2次元リスト(リストのリスト)として取得します [['商品コード', '商品名', '金額'], ['A0001', 'みかん', '100'], ['A0002', 'メロン', '200'], ['A0003', 'いちご', '300'], ['A0004', 'バナナ', '400'], ['A0005', 'トマト', '500']]
※見やすくするために改行しています
プログラムソースを確認します。
25 # 2次元リスト(リストのリスト)として取得(リスト内包表記を使用)
26 print("\n2次元リスト(リストのリスト)として取得します")
27 with open(file_name) as f: # ファイルを開く
28 reader = csv.reader(f) # CSVファイルの読み込み
29 list2d = [row for row in reader] # 2次元リストで取得
30 print(list2d) # 2次元リストを表示
31
32 #終了2
33 sys.exit()
28行目で reader()メソッドを使ってCSVファイルを読み込み、reader オブジェクトに格納しています。
29行目で リスト内包表記を使って、reader オブジェクトから2次元リストとして変数 list2d に格納しています。
30行目で 2次元リストを表示しています。
③ 数値にできるものだけを数値化
金額の列は数値です。数値の文字列は数値に変換しておくと便利です。
ソースコード #終了2 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
数値にできるものだけを数値化します [['商品コード', '商品名', '金額'], ['A0001', 'みかん', 100], ['A0002', 'メロン', 200], ['A0003', 'いちご', 300], ['A0004', 'バナナ', 400], ['A0005', 'トマト', 500]]
※見やすくするために改行しています
プログラムソースを確認します。
35 # 数値にできるものだけを数値化(リスト内包表記と三項演算子を使用)
36 print("\n数値にできるものだけを数値化します")
37 list2d = [[int(v) if v.isdecimal() else v for v in row ] for row in list2d] # 数値化
38 print(list2d) # 2次元リストを表示
39
40 #終了3
41 sys.exit()
37行目で リスト内包表記 と 三項演算子を使って数値にできる要素を数値に変換しています。
リスト内包表記
[式 for 任意の変数名 in イテラブルオブジェクト]
三項演算子
条件式が真のときに返す値 if 条件式 else 条件式が偽のときに返す値
④ 見出し行(ヘッダー)を取り除く
見出し行を取り除いてデータだけにしておくと便利です。
ソースコード #終了3 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
見出し行(ヘッダー)を取り除きます [['A0001', 'みかん', 100], ['A0002', 'メロン', 200], ['A0003', 'いちご', 300], ['A0004', 'バナナ', 400], ['A0005', 'トマト', 500]]
※見やすくするために改行しています
プログラムソースを確認します。
43 # 見出し行(ヘッダー)を取り除く(リスト内包表記を使用)
44 print("\n見出し行(ヘッダー)を取り除きます")
45 list2d = [row for row in list2d[1:]] # ヘッダーの除去
46 print(list2d) # 2次元リストを表示
47
48 #終了4
49 sys.exit()
45行目で 見出し行は1行目(インデックスは 0)なので、2行目以降(インデックスは 1)で2次元リストを作成しています。(リスト内包表記)
⑤ 行、要素、列を取得
ソースコード #終了4 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
3行目を取得します ['A0003', 'いちご', 300] 3行目の2列目を取得します いちご 3列目(金額)を取得します [100, 200, 300, 400, 500] 金額の合計を計算します 合計は 1500 です
プログラムソースを確認します。
51 # 行を取得
52 print("\n3行目を取得します")
53 datalist = list2d[2] # 0始まりのインデックスを指定
54 print(datalist) # 行のリストを表示
55
56 # 要素を取得
57 print("\n3行目の2列目を取得します")
58 data = list2d[2][1] # [行][列]の順で指定
59 print(data) # 要素を表示
60
61 # 列を取得
62 print("\n3列目(金額)を取得します")
63 list2d_T = [list(x) for x in zip(*list2d)] # 行と列を入れ替え
64 datalist = list2d_T[2] # 0始まりのインデックスを指定
65 print(datalist)
66
67 print("\n金額の合計を計算します")
68 total = sum(datalist) # リストの要素の合計値を計算
69 print("合計は、" + str(total) + " です")
70
71 #終了5
72 sys.exit()
行を取得(3行目)
53行目で 2次元リスト( list2d )から、3行目のデータ(インデックスは 2)を取り出しています。
要素を取得(3行目の2列目)
58行目で 2次元リスト( list2d )から、3行目のデータ(インデックスは 2)さらに 2列目の要素(インデックスは 1)を取り出しています。
列を取得(3列目の金額)
列を取得するにはまず行と列を入れ替えます。
63行目で リスト内包表記を使い、行と列を入れ替えて2次元リスト( list2d_T )に格納しています。
list2d_T の内容
[['A0001', 'A0002', 'A0003', 'A0004', 'A0005'],
['みかん', 'メロン', 'いちご', 'バナナ', 'トマト'],
[100, 200, 300, 400, 500]]
64行目で 2次元リスト( list2d_T )から、行と列を入れ替えているので3行目のデータ(インデックスは 2)を取り出しています。
金額の合計を計算
68行目で sum()関数を使って金額のリストの要素を合計しています。
5.CSVファイルの書き込み
① CSVファイルに1行ずつ書き込む
ソースコード #終了5 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** CSVファイルの書き込み **** csv_file2.csvに1行ずつ書き込みます csv_file2.csv の内容を確認しましょう
エクスプローラから、csv_file2.csv を開いて内容を確認してください。
プログラムソースを確認します。
74 print("\n*** CSVファイルの書き込み ****")
75
76 # CSVファイルに1行ずつ書き込む
77 print("\ncsv_file2.csvに1行ずつ書き込みます")
78 file_name = r"C:\Python\csv_file2.csv" # ファイルのフルパス名
79 with open(file_name, 'w', newline="") as f: # 書き込みモードでファイルを開く
80 writer = csv.writer(f, quoting=csv.QUOTE_NONNUMERIC)
81 writer.writerow(['商品コード', '商品名', '金額'])
82 writer.writerow(['A0001', 'みかん', 100])
83 print("csv_file2.csv の内容を確認しましょう")
84
85 #終了6
86 sys.exit()
79行目で CSVファイルを書き込みモード( 'w' )で開いています。
このとき、引数に newline="" を指定し忘れると、行毎に空行が入ってしまいます。
80行目の writer()メソッドの引数 quoting は以下の通りです。
・quoting=csv.QUOTE_ALL : すべての要素が引用符で囲まれる。
・quoting=csv.QUOTE_NONNUMERIC : 数値でない要素が引用符で囲まれる。
81行目と82行目の writerow()メソッドで行のデータを書き込んでいます。
② CSVファイルに2次元リストを書き込む
ソースコード #終了6 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
csv_file3.csvに2次元リストを書き込みます csv_file3.csv の内容を確認しましょう
エクスプローラから、csv_file3.csv を開いて内容を確認してください。
プログラムソースを確認します。
88 # CSVファイルに2次元リストを書き込む
89 print("\ncsv_file3.csvに2次元リストを書き込みます")
90 file_name = r"C:\Python\csv_file3.csv" # ファイルのフルパス名
91 list2d = [['商品コード', '商品名', '金額'],\
92 ['A0001', 'みかん', 100],\
93 ['A0002', 'メロン', 200],\
94 ['A0003', 'いちご', 300],\
95 ['A0004', 'バナナ', 400],\
96 ['A0005', 'トマト', 500]]
97 with open(file_name, 'w', newline="") as f: # 書き込みモードでファイルを開く
98 writer = csv.writer(f, quoting=csv.QUOTE_NONNUMERIC)
99 writer.writerows(list2d)
100 print("csv_file3.csv の内容を確認しましょう")
101
102 #終了7
103 sys.exit()
90行目で 変数 file_name に csv_file3.csv のフルパスファイル名をセットしています。
91行目から96行目で CSVファイルに書き込む2次元リストを用意しています。
Pythonでは、行の末尾に \ を付けることで、コーディングを複数行に記述することができます。
97行目で CSVファイルを書き込みモード( 'w' )で開いています。
引数の newline="" は、行毎に空行が入らないようにしています。
98行目で 数値でない要素が引用符で囲まれるように指定しています。
99行目の writerows()メソッドで複数行のデータを書き込んでいます。
③ 追記モードでCSVファイルに書き込む
ソースコード #終了7 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
csv_file3.csvにデータを追加します csv_file3.csv の内容を確認しましょう
エクスプローラから、csv_file3.csv を開いて内容を確認してください。
プログラムソースを確認します。
105 # 追記モードでCSVファイルに書き込む
106 print("\ncsv_file3.csvにデータを追加します")
107 with open(file_name, 'a', newline="") as f: # 追記モードでファイルを開く
108 writer = csv.writer(f, quoting=csv.QUOTE_NONNUMERIC)
109 writer.writerow(['A0006', 'ぶどう', 600])
110 print("csv_file3.csv の内容を確認しましょう")
111
112 #終了8
113 sys.exit()
107行目で CSVファイルを追記モード( 'a' )で開いています。
108行目で 数値でない要素が引用符で囲まれるように指定しています。
109行目の writerow()メソッドで行のデータを書き込んでいます。
④ CSVファイルのデータを修正する
商品コード 'A0005' の商品名を 'トマト' から 'りんご' に修正します。
ソースコード #終了8 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
csv_file3.csvのデータを修正します csv_file3.csv の内容を確認しましょう
エクスプローラから、csv_file3.csv を開いて内容を確認してください。
プログラムソースを確認します。
115 # CSVファイルのデータを修正する
116 print("\ncsv_file3.csvのデータを修正します")
117 with open(file_name) as f: # ファイルを開く
118 reader = csv.reader(f) # CSVファイルの読み込み
119 list2d = [row for row in reader] # 2次元リストで取得
120 list2d = [[int(v) if v.isdecimal() else v for v in row ] for row in list2d] # 数値化
121
122 for i in range(len(list2d)):
123 datalist = list2d[i]
124 if list2d[i][0] == "A0005":
125 list2d[i][1] = "りんご"
126
127 with open(file_name, 'w', newline="") as f: # 書き込みモードでファイルを開く
128 writer = csv.writer(f, quoting=csv.QUOTE_NONNUMERIC)
129 writer.writerows(list2d)
130 print("csv_file3.csv の内容を確認しましょう")
131
132 #終了9
133 sys.exit()
117行目で csv_file3.csv を開いています。
118行目から120行目で ファイルを読み込み、2次元リスト( list2d )に格納して、数値にできる要素を数値化しています。
122行目から125行目の for文で、商品コードが 'A0005' であれば 商品名を 'トマト' から 'りんご' に書き換えています。
127行目で CSVファイルを書き込みモード( 'w' )で開いています。
引数の newline="" は、行毎に空行が入らないようにしています。
129行目の writerows()メソッドで2次元リストのデータを書き込んでいます。
6.pandasでのCSVファイルの読み書き
① pandasを使ったCSVファイルの修正
pandasを使って、商品コード 'A0005' の商品名を 'りんご' から 'レモン' に修正します。
ソースコード #終了9 の1行下の sys.exit() の先頭に「 # 」を入れてコメントにします。
Ctrl キーを押しながら、 S キーを押して、ソースコードを上書き保存します。
コマンドプロンプトで F3 キーを押して、 Enter キーを押下します。
以下のように表示されます。
*** pandasでのCSVファイルの読み書き **** csv_file3.csvのデータをpandasを使って修正します 【修正前】 商品コード 商品名 金額 0 A0001 みかん 100 1 A0002 メロン 200 2 A0003 いちご 300 3 A0004 バナナ 400 4 A0005 りんご 500 5 A0006 ぶどう 600 【修正後】 商品コード 商品名 金額 0 A0001 みかん 100 1 A0002 メロン 200 2 A0003 いちご 300 3 A0004 バナナ 400 4 A0005 レモン 500 5 A0006 ぶどう 600 csv_file3.csv の内容を確認しましょう
プログラムソースを確認します。
135 print("\n*** pandasでのCSVファイルの読み書き ****")
136
137 # pandasを使ったCSVファイルの修正
138 print("\ncsv_file3.csvのデータをpandasを使って修正します")
139 df = pandas.read_csv(file_name, encoding='shift_jis')
140 print("\n【修正前】")
141 print(df)
142
143 for index, data in df.iterrows():
144 商品コード = str(data['商品コード'])
145 商品名 = str(data['商品名'])
146 if 商品コード == "A0005":
147 df.loc[index, '商品名'] = "レモン"
148 print("\n【修正後】")
149 print(df)
150
151 df.to_csv(file_name, encoding='shift_jis', index=False)
152 print("\ncsv_file3.csv の内容を確認しましょう")
153
154 sys.exit()
139行目で pandasの read_csv()メソッドで csv_file3.csv を読み込んで、データフレーム( df )にセットしています。
143行目から147行目の for文で、商品コードが 'A0005' であれば 商品名を 'レモン' に書き換えています。
151行目で pandasの to_csv()メソッドで csv_file3.csv に書き込んでいます。
pandasを使った方が、コーディングが簡潔になります。
pandasについては、別章で詳しく解説します。
| <テキストファイルの読み書き | CSVファイルの読み書き | xlwingsを使った Excelファイルの読み書き> |

